
Human-in-the-Loop Design Patterns for AI
Eight practical patterns to avoid over-engineering and under-engineering AI oversight
There's a conversation that comes up in nearly every AI engagement we run. Someone says "we need a human in the loop" and everyone nods. It sounds sensible. Responsible, even. But then the room goes quiet, because nobody has worked out what that actually means in practice.
Does it mean a person reviews every single output before it goes anywhere? Does it mean someone checks a sample? Does it mean the AI just runs and someone looks at the logs later? These are very different design choices, and they lead to very different outcomes.
Here at DataSing, we've come to see human-in-the-loop (HITL) not as a feature you bolt on at the end, but as an operating choice you make at the start. It's part of the system design. And getting it wrong is one of the most common reasons AI projects either stall or fail.
The two failure modes (and why they keep happening)
Most organisations that stumble with AI oversight fall into one of two predictable traps.
Over-engineered oversight is the first one. Every AI output must be reviewed by a human before it can be used, sent, or acted on. On paper this looks safe. In practice, it kills the value proposition. The AI becomes slow and expensive. Staff spend their time reviewing outputs rather than doing higher-value work. Eventually, people stop using the tool because it takes longer than just doing the task manually. The AI pilot quietly dies, and leadership concludes that "AI isn't ready for us."
Under-engineered oversight is the other trap. The team is excited about what the AI can do, skips the control design, and pushes outputs straight to users or into workflows with minimal checks. It works fine for a while, right up until it doesn't. An incorrect summary goes to a minister. A classification error triggers the wrong process. A chatbot gives advice that's confidently wrong. Trust evaporates. The programme gets shut down, and the organisation becomes gun-shy about AI for the next two years.
Both of these are avoidable. The way to avoid them is to match the level of oversight to the level of risk, deliberately and specifically, rather than applying a blanket rule.
What determines the right pattern?
Before choosing how to implement HITL, you need to understand what's driving the risk. We use six decision factors:
Impact severity. What's the harm if the output is wrong? A misclassified internal note is very different from an incorrect enforcement recommendation. The higher the potential harm, the more oversight you need.
Reversibility. Can you undo the action or correct the outcome? An email that's already been sent to a client can't be unsent. A draft document that sits in a queue can be edited before it goes anywhere. Irreversible actions need harder gates.
Uncertainty. How confident can the system be in its output, and can you measure that confidence? Some tasks produce outputs where confidence scoring is straightforward (classification, for example). Others are inherently uncertain (open-ended text generation). Where confidence is measurable, you can use it to route decisions.
Data sensitivity. Is the AI working with personal information, health data, commercially sensitive material, or security-classified content? Sensitive data raises the stakes on every other factor.
Explainability needs. Do you need to explain how a decision was reached, and to whom? If auditors, ministers, or the public might ask "how did you arrive at this?", you need a clear trail from input to output, and human decision points along the way.
User capability. Can the people receiving the output actually spot errors? A subject matter expert reviewing an AI-drafted policy analysis is very different from a frontline worker receiving an AI-generated notification they're expected to send as-is.
The pattern library: eight ways to keep humans in the loop
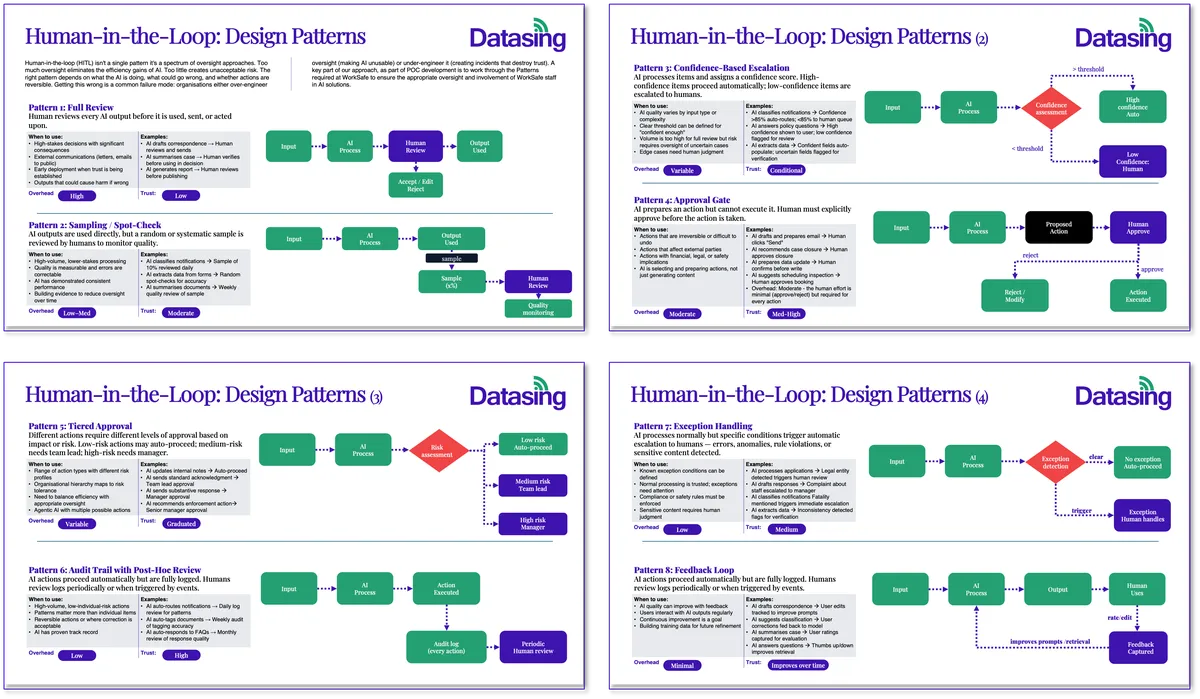
HITL is not a single gate. It's a toolkit. Here are eight patterns we use, and the situations each one fits best. Real systems almost always combine two to four of these, not just one.
Pattern 1: Full review. Every AI output is reviewed by a human before it's used, sent, or acted on. The human can accept, edit, or reject. This is the right pattern when the stakes are high and the consequences of getting it wrong are serious.
Pattern 2: Sampling and spot-checks. AI outputs are used directly, but a random or systematic sample is reviewed by humans to monitor quality. This works well for high-volume, lower-stakes processing where quality is measurable and errors are correctable.
Pattern 3: Confidence-based escalation. The AI processes items and assigns a confidence score. High-confidence items proceed automatically. Low-confidence items are routed to a human for review. This is one of the most practical patterns for balancing efficiency with safety.
Pattern 4: Approval gate. The AI prepares an action but cannot execute it. A human must explicitly approve before the action is taken. Essential for actions that are irreversible or affect external parties.
Pattern 5: Tiered approval. Different actions require different levels of approval based on their impact or risk. Low-risk actions may auto-proceed. Medium-risk actions need a team lead. High-risk actions need a manager.
Pattern 6: Post-hoc audit trail. AI actions proceed automatically, but everything is fully logged. Humans review logs periodically or when triggered by events. Right for high-volume, low-individual-risk actions.
Pattern 7: Exception handling. AI processes normally, but specific conditions trigger automatic escalation to humans. These might be errors, anomalies, rule violations, or sensitive content detected.
Pattern 8: Feedback loop. Human edits, corrections, and ratings are captured and used to continuously improve prompts, retrieval, models, and rules. This is the mechanism by which the system gets better over time.
Combining patterns in practice
No real system uses just one pattern. A well-designed AI solution typically layers two to four patterns together.
For example, an AI that drafts correspondence for a government agency might use Pattern 4 (approval gate) for all external communications, Pattern 3 (confidence-based escalation) for internal classifications, Pattern 6 (audit trail) for routine tagging, and Pattern 8 (feedback loop) across the board. That's four patterns working together, each calibrated to a different part of the workflow based on the risk profile of that specific action.
The point is to be intentional. Every AI output or action should have a defined oversight path, chosen based on the decision factors above, not left to chance.
Where HITL fits in the AI delivery lifecycle
HITL isn't something you design once at the start and forget. It needs to be considered at every stage of an AI solution's lifecycle.
Discovery. Classify use cases by risk and reversibility. Decide what failure modes are acceptable and which are not. This is where you determine whether a particular use case needs full review or can tolerate a lighter touch.
Design. Select the patterns that apply. Define what human decision points actually look like: who reviews, what they see, what options they have, how long they have to respond. Wire the patterns into the solution architecture, not as an afterthought but as a first-class design concern.
Build. Implement the controls. This includes role-based and attribute-based access controls, logging infrastructure, provenance tracking, escalation routing, and the interfaces humans use to review and approve.
Evaluate. Create "golden test sets" of known-good and known-bad examples. Run red-team scenarios to test whether escalation thresholds actually fire when they should. Validate that approval gates can't be bypassed.
Operate. Monitor for drift. Models change, data changes, and the world changes. Confidence thresholds that were right at launch may need recalibrating three months later. Crucially, as trust in the system grows through evidence, oversight patterns can evolve.
Practical guardrails that make it real
Regardless of which patterns you choose, four guardrails should be non-negotiable:
Provenance. Every AI output should be traceable to its sources, the version of the model or prompt that produced it, and the inputs it was given. If someone asks "where did this answer come from?", you need to be able to show them. This is exactly what our Evidence Packs deliver.
Transparency. The system should be able to explain why it produced a particular output or recommended a particular action, in plain language, not just in technical logs.
Auditability. Inputs, outputs, decisions, approvals, and actions all need to be logged in a way that's immutable and accessible. This isn't optional, especially for public sector organisations operating under the Public Service AI Framework.
Safety by default. The system should operate on least privilege principles. AI should only access the data it needs for the task at hand. Retrieval should be scoped to relevant sources. Sensitive information should be redacted from outputs where appropriate.
New Zealand's Public Service AI Framework and the GCDO's responsible AI guidance are clear: agencies need to use AI in ways that are safe, transparent, and accountable. HITL design patterns are how you make that real, not as a compliance exercise, but as a genuine operating capability. Our AI Guardrails enforce these principles automatically at runtime across all our AI solutions.
Written by
DataSing Team
AI Governance Specialists